Inception Labs lanceert Diffusion Large Language Model

In een baanbrekende ontwikkeling heeft Inception Labs vandaag de eerste commercieel beschikbare Diffusion Large Language Model (dLLM) genaamd Mercury Coder gelanceerd, die potentieel de toekomst van kunstmatige intelligentie fundamenteel kan veranderen. Deze innovatieve technologie onderscheidt zich van traditionele auto-regressieve taalmodellen door een parallel generatieproces dat significant sneller en efficiënter is.
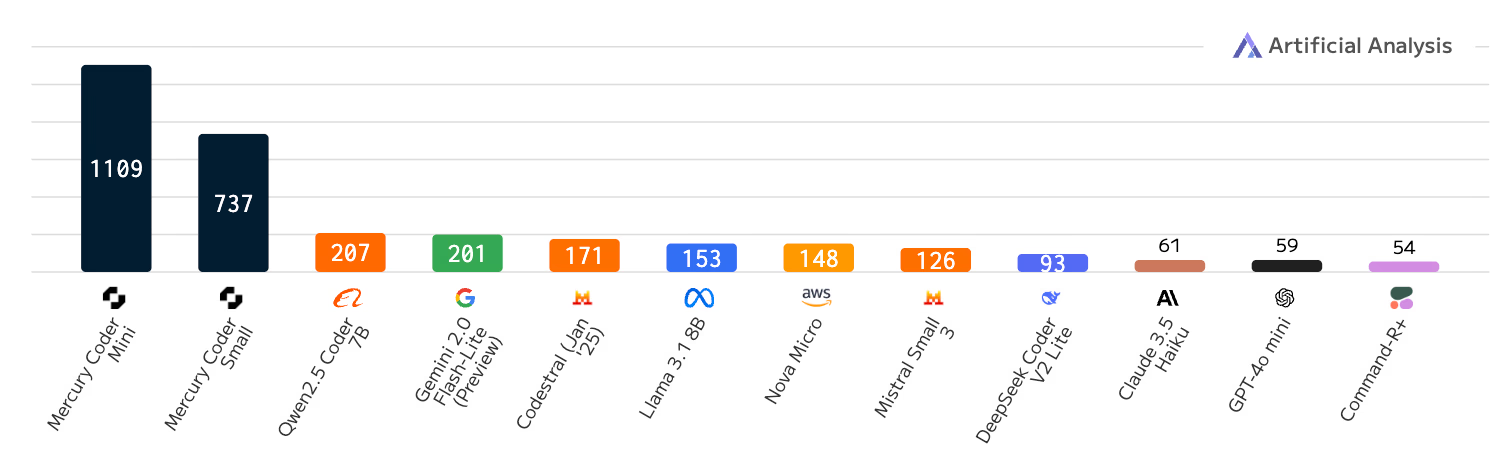
Onderzoek wijst erop dat diffusion LLMs tot 10x sneller kunnen werken dan bestaande modellen, met snelheden tot 1000 tokens per seconde. Toonaangevende AI-experts zoals Andrej Karpathy en Andrew Ng hebben de ontwikkeling enthousiast verwelkomd als een veelbelovende doorbraak in machinaal leren.
De diepgaande analyse onthult meerdere cruciale perspectieven op deze technologische innovatie. Diffusion LLMs introduceren een radicaal andere benadering van taalverwerking waarbij tokens parallel in plaats van sequentieel worden gegenereerd. Dit contrasteert scherp met huidige auto-regressieve modellen zoals ChatGPT, die elke token afhankelijk van de vorige genereren.
De technische implicaties zijn verstrekkend. Door gebruik te maken van diffusietechnieken - vergelijkbaar met die in beeldgeneratiemodellen zoals Stable Diffusion - kunnen deze nieuwe modellen complexe teksten genereren door systematisch ruis te verwijderen. Dit opent potentieel geheel nieuwe mogelijkheden voor reasoning, foutcorrectie en meer gecontroleerde tekstgeneratie.
Businessmatig gezien vertegenwoordigt dit een significante verschuiving. De claim van 5-10x hogere verwerkingssnelheid kan substantiële kostenbesparingen en performanceverbeteringen betekenen voor organisaties die AI-taalmodellen gebruiken. Bovendien suggereert de competitieve prestatie van modellen zoals LLaDA dat diffusion LLMs serieuze concurrentie kunnen vormen voor gevestigde auto-regressieve architecturen.
Echter, belangrijke uitdagingen blijven bestaan. Schaalbaarheid, complexiteit van training en volledige interpreteerbaarheid zijn nog niet volledig bewezen. De technologie lijkt voorlopig meer complementair dan vervangend voor bestaande modellen.
De ethische en maatschappelijke implicaties zijn eveneens significant. Snellere, meer gecontroleerde AI-gegenereerde tekst kan doorbraken betekenen in disciplines als programmeren, onderzoek en communicatie, maar roept tegelijkertijd vragen op over authenticiteit en mogelijke verkeerde toepassingen.